Co je to Docker a k čemu je dobrý

Hlavní výhody Docker a jeho nejzajímavější funkce.

Docker v poslední době nabývá na popularitě. O Dockeru můžeme mluvit jako o kontejnerové virtualizaci, což je správně, ale určitě to plně nevystihuje jeho účel. Možná je přesnější hovořit o izolaci procesů. Ani to ale nevyjádří přesnou podstatu.
O Dockeru lze uvažovat i jako o virtualizaci, která nemá žádný overhead. Start kontejneru je okamžitý, kernel se sdílí s podkladovým OS a ani nedochází k žádnému zpomalení při vlastním běhu programu, resp. jde vlastně o fork systemd procesu. Nejlepší tedy bude mluvit o Dockeru jako o Dockeru.
Výhody používání Docker
Docker, stejně jako jiné kontejnerové virtualizace, odstraňuje jeden z velkých problémů samotné virtualizace – nároky na hardware. Některé virtualizace mohou spotřebovat až 1/5 výkonu. Klasická virtualizace, jak ji zná dnes asi už každý, pracuje s modelem hardware – hostitelský OS – hypervisor – klientský OS – aplikace.
U Dockeru je to jinak. Kontejnery totiž sdílí jednu linuxovou instanci, nad kterou se pak jednotlivé izolované procesy spouští. Pracuje tedy s modelem hardware – OS – docker engine – a pak už rovnou aplikace.
Technologie Docker není náhradou za LXC. „LXC“ se odkazuje na jádro Linuxu (jmenovitě jmenných prostorů a řídících skupin), které umožňuje navzájem vytvářet procesy mezi jednotlivými oblastmi a řídit přidělování prostředků. Na vrcholu této nízké úrovně funkcí jádra nabízí Docker nástroj na vysoké úrovni s mnoha výkonnými funkcemi.
Docker je (narozdíl od strojů) optimalizován pro nasazení aplikací. To se odráží v jeho rozhraní API, uživatelském rozhraní, filozofii návrhu a dokumentaci. Naproti tomu skripty LXC se zaměřují na kontejnery jako lehké stroje – v podstatě na servery, které se bootují rychleji a potřebují méně paměti.

Nejzajímavějši funkce Docker
Přenosné nasazení mezi stroji
Docker definuje formát pro zabalení aplikace a všech jejích závislostí do jednoho objektu nazvaného kontejner. Docker jako kontejner lze v přeneseném smyslu slova skutečně s kontejnerem srovnávat. Cokoliv, myšleno aplikace a její prostředí, do něj uzavřete, můžete snadno přenést kamkoliv. Kdekoliv ho použijete bude fungovat stále stejně.
Automatický build
Docker obsahuje nástroj pro vývojáře k automatickému sestavení kontejneru ze zdrojového kódu s plnou kontrolou závislostí aplikací, vytvářením nástrojů, balením, apod. Volně jsou k použití make, maven, chef, puppet, salt, balíčky Debian, RPM, zdroj tarballs nebo jakékoli kombinace výše uvedených, bez ohledu na konfiguraci strojů.
Verze
Docker obsahuje funkce typu git pro sledování následných verzí kontejneru, kontrolu rozdílu mezi verzemi, zavádění nových verzí, rollback atd. Historie také zahrnuje, jak byl kontejner sestaven a kým. Získáte tak sledovatelnost celé cesty z produkčního serveru až k vývojáři. Docker také provádí inkrementální nahrávání a stahování, podobně jako git pull, takže nové verze kontejneru mohou být přenášeny pouze odesláním diffs.
Klony
Každý kontejner může být použit jako “rodičovský obraz” pro vytvoření více specializovaných komponent. To lze provést ručně nebo jako součást automatizovaného buildu.
I když ve způsobu používání Dockeru nikomu nic nebrání, měly by se v rámci udržitelnosti vytvářet pouze kontejnery obsahující jednu aplikaci. Pokud použijete aplikací více, vzniká riziko konfliktních závislostí, a to jde přímo proti filosofii Dockeru, kterou je snadná přenositelnost. Proto jsou od více-aplikačních kontejnerů vývojáři samotným Dockerem odrazováni.
Při definování docker image je především nutné dodržet alespoň tato pravidla:
- mít explicitně deklarované a izolované závislosti
- konfiguraci mít uloženou do prostředí
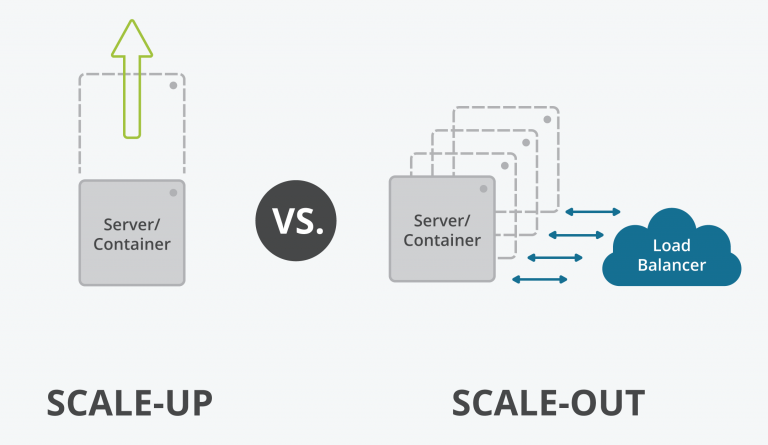
- počítat s možností neomezeného škálování aplikace nahoru i dolů
Bezstavové vs. stavové aplikace
Obecně se pak dá říct, že je Docker nejsilnější v provozu bezstavových aplikací. U aplikací stavových, jako jsou typicky databázové servery, dává jeho použití smysl pouze v určitých případech. U jednoinstančních instalací Dockeru může být smysl v provozování stavových aplikací pouze pro účely nějakých development nebo testing verzí.
Pokud se ale budeme bavit o provozování Dockeru na nějaké větší platformě s množstvím fyzických serverů, tak mohou být škálovatelné stavové aplikace zajímavou možností, jak v závislosti na vytížení aplikace upravovat její výkon. Typicky Docker Mysql Cluster.
Na závěr lze říci, že se jedná o velmi sofistikovaný a výkonný nástroj pro development a testing aplikací. Pro jeho použití v produkčním prostředí je ale nutné projít trošku delší cestu.
Pokud hledáte prostředí pro větší projekty, které je postavené na Dockeru, mrkněte na naší službu Managed Platform for Kubernetes. Ta nabízí plně automatizovanou infrastrukturu pro Docker aplikace.