

Horizontální škálování MySQL

Jak efektivně rozložit databázi do několika serverů a čeho se vyvarovat.

Databázové servery jsou kritickou částí infrastruktury každého webového projektu a se vzrůstající velikostí roste také jejich význam. Dříve či později se ale dostaneme do stavu, kdy výkonové požadavky na databázi nebude možné řešit pouze přidáváním další paměti a vylepšováním procesorů. Navyšování zdrojů jednoho serveru má své technické limity a časem skončíme u nutnosti rozložit zátěž do více serverů.
Před realizací takového kroku je více než vhodné si ujasnit, čeho chceme dosáhnout. Některé modely distribuce zátěže nám pouze pomohou zvládnout vyšší množství požadavků, některé nám vyřeší i problém případné nedostupnosti jednoho ze strojů.

Škálování, vysoká dostupnost a další pojmy
Nejdříve se pojďme podívat na základní pojmy, se kterými budeme dnes operovat. Není jich mnoho, ale bez jejich znalosti se nehneme dál. Zkušení škálovači mohou tuto část s klidným svědomím přeskočit.
Škálovatelnost (scalability)
Schopnost systému (v našem případě databázového prostředí) reagovat na zvýšenou nebo sníženou potřebu zdrojů. V praxi rozeznáváme dva základní druhy škálování a to škálování vertikální a horizontální.
Při vertikálním škálování zvyšujeme prostředky, které má daná databáze k dispozici. Typicky se jedná o přidávání dostupné paměti serveru a zvyšování počtu jader. Vertikálně lze škálovat prakticky libovolnou aplikaci, dříve či později ale narazíme na hardwarové limity platformy.
Proti tomu stojí horizontální škálování, kdy výkon aplikace zvyšujeme přidáváním dalších serverů. Tímto způsobem můžeme zvyšovat výkon prakticky neomezeně, aplikace musí ale s tímto způsobem distribuce počítat.
Vysoká dostupnost (high availability)
Schopnost systému reagovat na výpadek části systému. Předpokladem pro vysokou dostupnost je schopnost provozovat aplikaci ve více instancích.
Další instance mohou být plnohodnotně zastupitelné a zpracovávat požadavky paralelně (active-active setup) nebo mohou být v režimu stand-by, kdy na sebe pouze zrcadlí data, ale nejsou schopny odbavovat provoz (active-passive setup). V případě problému je vybrána jedna z instancí v passive režimu a je převedena do active.
Master node
Řídící komponenta systému. V případě databází se jedná o instanci v režimu čtení i zápisu. Pokud máme více plnohodnotných master nodů, mluvíme o tzv. multi-master setupu.
Slave node
Záložní kopie dat. V klidovém stavu na sebe zrcadlí data a funguje v režimu pouze pro čtení. Pokud dojde k výpadku master nodu, je jeden ze slave nodů vybrán a převeden do master režimu. Po opravě původního master nodu se buď nový master vráti do stavu slave, nebo zůstává masterem a původní master je připojen jako slave node.
Asynchronní replikace
Po zápisu dat na master nodu je tento zápis potvrzen klientovi a zapsán do transakčního logu. Později v čase je tato změna replikována na slave nody. Dokud nedojde k replikaci, jsou nová nebo změněná data dostupná pouze na master nodu a v případě jeho výpadku jsou nedostupná. Asynchronní replikace je typická pro MySQL.
Synchronní replikace
Klientovi je zápis potvrzen až poté, co jsou data zapsaná na všechny nody v clusteru. Odpadá zde riziko výpadku nových dat (data jsou změněna všude nebo nikde), je ale výrazně náchylnější k problémům na síti mezi nody.
V případě síťového výpadku je výkon clusteru dočasně degradován, nebo je dokonce dočasně zastaven příjem nových požadavků na změnu dat. Tento způsob replikace se využívá v případě multi-master setupů v kombinaci s pluginem Galera.
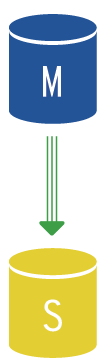
Master – Slave replikace
Master – slave je základní podoba replikace databázového clusteru. V tomto návrhu máme jeden řídící master node, který přijímá všechny typy dotazů. Slave node (případně více nodů) na sebe zrcadlí změny pomocí asynchronní replikace. Slave nody tedy nemusí mít k dispozici nejnovější kopii dat.
Pokud dojde k výpadku master nodu, je vybrán slave s nejnovější kopií dat a ten je prohlášen za nový master. Každý slave node si ověřuje, o kolik je zpožděn oproti master nodu. Tuto hodnotu můžeme zjistit v proměnné Seconds_behind_master a je velmi důležité ji monitorovat. Vzrůstající hodnota ukazuje na problém v replikaci změn na master nodu.
Slave node funguje v režimu read-only, dokáže tedy odbavovat dotazy typu select. V tom případě mluvíme o tzv. read/write splitu, o kterém se zmíníme dále.
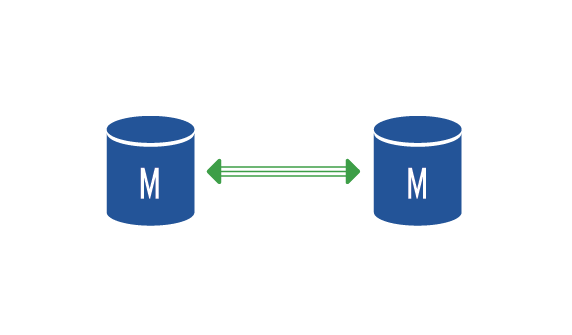
Master – Master replikace
Master – master setup je takový, kde máme právě dva master nody. Oba dva jsou schopni odbavovat všechny typy dotazů, mezi nimi ale probíhá asynchronní replikace. To přináší nevýhodu v případě, kdy data zapsaná na první node nemusí být okamžitě dostupná na druhém nodu. V praxi toto nastavujeme tak, že každý node je zároveň slave nodem druhého.
Tento setup se hodí v okamžiku, kdy před MySQL servery postavíme loadbalancer, který na každý stroj směřuje polovinu spojení. Každý node je ale samostatným masterem, neví nic o tom, že druhý node je taky v master režimu a je tedy nutné nastavit krok auto incrementu na 2. Pokud toto neprovedeme, bude docházet ke kolizím primárních klíčů, které využívají auto increment.
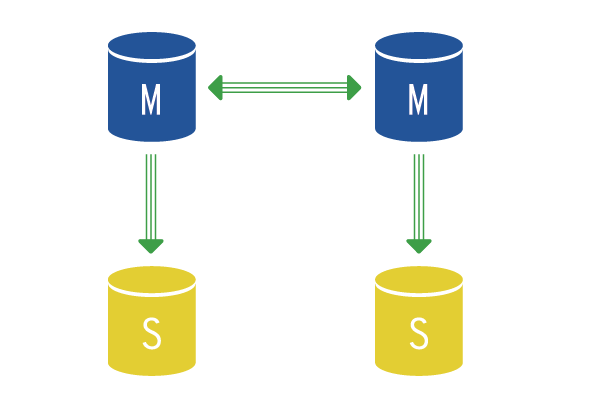
Každý z master nodů může mít u sebe další slave nody, které lze použít pro čtení dat (read/write split) a jako zálohu.
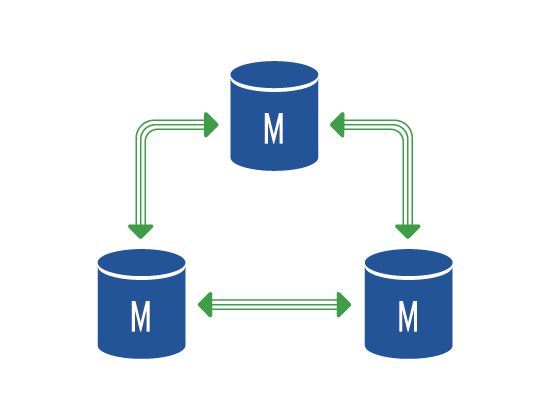
Multi – Master replikace
O multi-master setupu mluvíme v okamžiku, kdy máme v clusteru více než dva master nody. Tento setup nelze postavit v základní MySQL, ale musíme použít implementaci protokolu wsrep, např. plugin Galera.
Wsrep implementuje synchronní replikaci a tedy je velmi náchylný na problém na straně sítě a vyžaduje také časovou synchronizaci všech nodů. Umožňuje ale zasílat všechny typy dotazů na všechny nody v clusteru, takže je velmi vhodný pro řešení loadbalancingu. Nevýhodou je fakt, že všechny replikované tabulky musí používat engine innodb, tabulky využívající jiný engine nebudou replikovány.
Shardování
Shardování je dělení dat na logické segmenty. V MySQL se pro tento způsob ukládání dat používá název partitioning a prakticky znamená, že data jedné tabulky jsou rozkládány na různé servery, různé tabulky nebo různé datové soubory v rámci jednoho serveru.
Shardování dat je vhodné v situaci, kdy máme data, která tvoří oddělené skupiny. Typickou ukázkou jsou např. historické záznamy (shardujeme podle času) nebo data uživatelů (shardy vytváříme podle ID uživatele). Díky rozkladu dat do samostatných skupin můžeme efektivně kombinovat různé druhy storage, kdy aktuální data máme na rychlých SSD discích a starší data, u kterých nepředpokládáme časté využití, ukládáme na levnější rotační disky.
Shardování se velmi často používá v NoSQL databázích, napřiklad ElasticSearch.
Read – Write splitting
V režimu Master-Slave replikace máme k dispozici výkon slave nodů, který ale nemůžeme použít pro zápisové operace. Pokud ale máme aplikaci, kde tvoří většinu dotazů pouze selecty (typicky webové projekty), můžeme jejich výkon využít pro čtení. V tomto případě tedy aplikace směřuje zápisové operace (insert, delete, update) na master node, ale selecty posílá na skupinu slave nodů.
Díky tomu, že jeden master node může mít mnoho slave nodů, pomůže nám read/write splitting se zvýšením odezvy celé aplikace pomocí rozkládání čtecích operací.
Toho chování není potřeba na straně databázového serveru nijak konfigurovat, je ale potřeba jej řešit na straně aplikace. Nejjednodušší variantou je v aplikaci udržovat dvě spojení, jedno pro zápis a druhé pro čtení. Aplikace se pak podle typu dotazu rozhoduje, jaké spojení pro daný dotaz použije.
Druhou variantou, vhodnou pro případ, kdy nejsme schopni implementovat read/write split na úrovni aplikace, je využití aplikační proxy, která rozumí dotazům a je schopna je automaticky předávat na odpovídající nody. Aplikace si drží pouze jedno spojení na proxy a nestará se o druhy dotazů. Typickým představitelem takové proxy je řešení od Maxscale. Bohužel se jedná o komerční produkt, nabízí ale verzi zdarma s omezením na tři databázové nody.
Škálujeme za vás
Nemáte kapacitu či chuť na to, spravovat si a škálovat databáze sami? Uděláme to za vás.
Postaráme se i o velmi složitý provoz a vyladění široké škály databází. Zajistíme jejich maximální stabilitu, dostupnost a škálovatelnost. Náš tým adminů spravuje desítky tisíc databázových serverů a clusterů, takže budete v rukou opravdových expertů.







