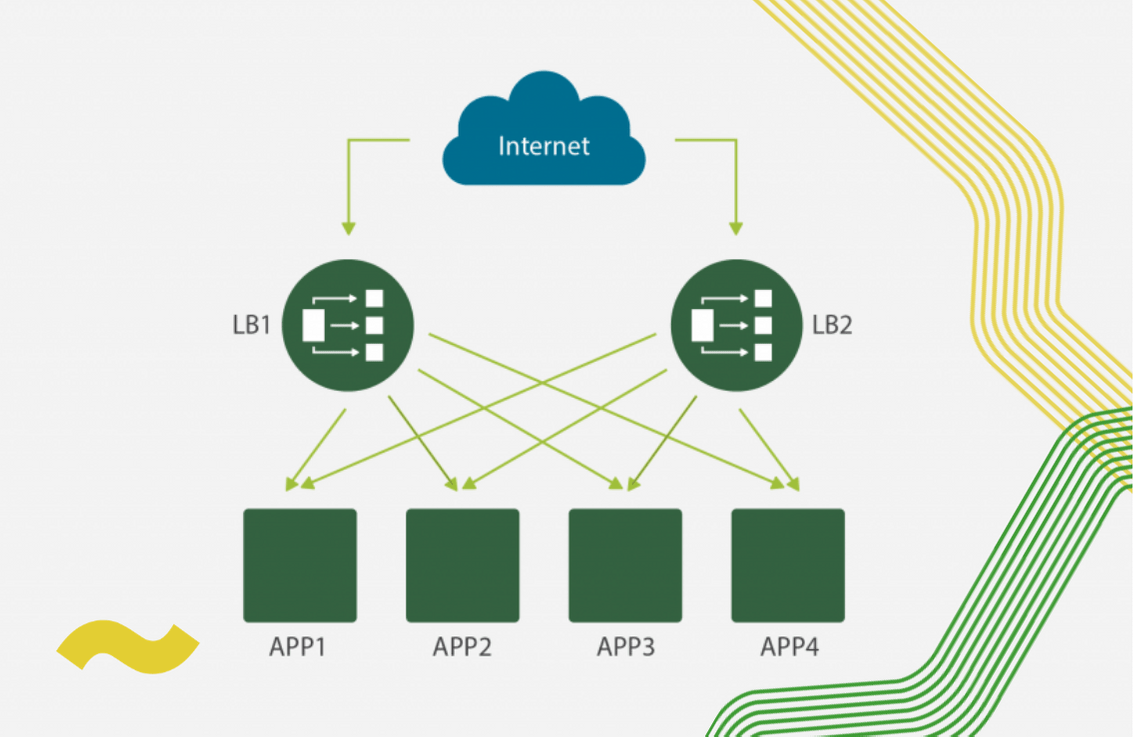
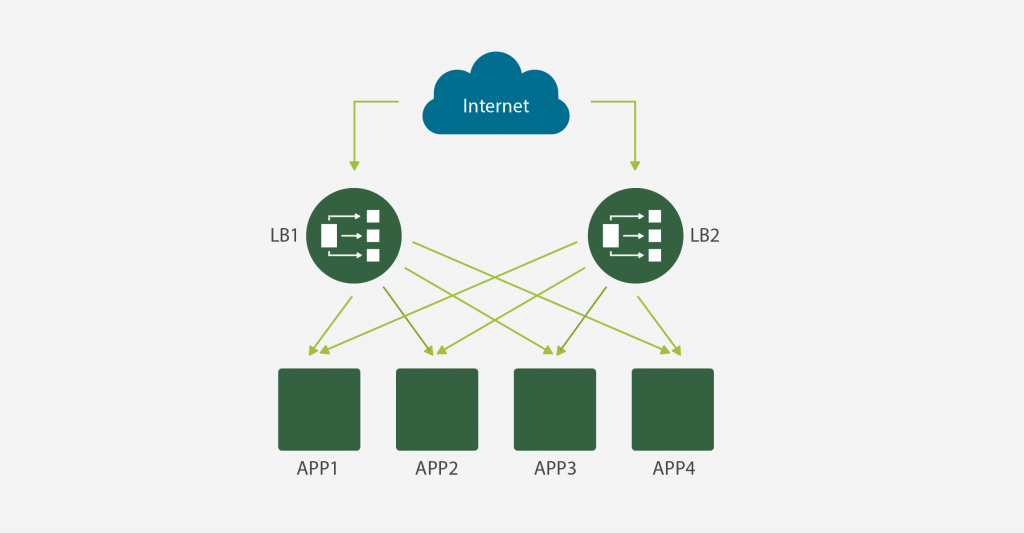
9 důvodů proč podlehnout trendu DevOps a kontejnerových technologií

DevOps a kontejnerizace nejsou jen pomíjivé trendy. Můžou vám pomoct zefektivnit vývoj i zvýšit spokojenost zákazníků. Tady je top 9 důvodů.

DevOps a kontejnerizace patří mezi oblíbené IT buzzwordy dnešní doby. Nikoli bezdůvodně. Kombinace těchto přístupů je jedním z důvodů, proč se daří práci vývojářů stále zefektivňovat. V tomto článku se zaměříme se na 9 hlavních důvodů, proč by se i vám tyto vývojové přístupy mohly vyplatit.
Pár rychlých vysvětlivek na úvod
DevOps je složenina z anglických slov Development (Vývoj) a Operations (Provoz), a jde vlastně o přístup k vývoji software, který klade důraz na spolupráci vývojářů s IT odborníky starajícími se o provoz aplikací. To vede k mnoha výhodám, které si tu postupně rozebereme.
Kontejnerizace do DevOps skvěle zapadá a můžeme ji chápat jako podpůrný nástroj DevOps přístupu. Podobně jako kontejnery fyzické, které standardizovaly přepravu zboží, softwarové kontejnery představují standardní jednotku „přepravy“ softwaru. Díky tomu je IT odborníci mohou nasadit napříč prostředími v podstatě bez úprav (podobně jako fyzický kontejner můžete bez problému přeložit z lodi na vlak nebo na kamion).
Top 9 výhod DevOps a kontejnerů
1) Synergie mezi týmy
U DevOps přístupu spolu vývojáři a admini úzce spolupracují a účastní se všech fází vývojového procesu. Tyto dva světy bývaly tradičně striktně oddělené, ale jejich de facto sloučení má mnohé výhody.
Spolupráce vede k větší efektivitě celého vývojového i operačního procesu a tím i k jeho zrychlení. Neméně důležitým aspektem je i to, že kooperace kolegů ze dvou odlišných oblastí s sebou často nese nejrůznější inovativní, „out of the box řešení“, na která by jinak nikdo nepřišel.
2) Transparentní komunikace

Častým problémem nejen v IT firmách bývá kvalitní komunikace. Každý má spoustu práce a hledí si svého. Výsledkem pak bývají nedorozumění, chybné předpoklady a z toho plynoucí konflikty a zbytečná práce.
Součástí myšlenky DevOps je zavedení transparentní a pravidelné komunikace mezi vývojáři a administrátory, díky čemuž všichni táhnou za jeden provaz. Obě skupiny jsou také zapojeny do všech fází tvorby aplikací či jejich částí.
3) Méně bugů a dalších „nehod“
Mezi principy DevOps patří také časté vydávání menších částí aplikací, oproti méně frekventovaným releasům větších celků. Díky tomu eliminujete riziko dopadu chybného kódu na celek. Jinak řečeno: pokud se náhodou něco pokazí, nerozbijete tím celou aplikaci. Spolu s důrazem na důkladné testování tento postup vede k výrazně nižší frekvenci výskytu bugů a jiných chyb.
Pokud spolu s DevOps využijete kontejnery, můžete těžit z jejich standardizace. Ta mimojiné zajišťuje, že vývojové, testovací i produkční prostředí (tj. kde aplikace výsledně běží) je definováno identicky. Tím výrazně snížíte výskyt bugů, které se při vývoji a testování neprojevily, a ukážou se až při spuštění v produkčním prostředí.
4) Snazší hledání i oprava chyb
Opravě případných chyb a zajištění hladkého chodu aplikace napomáhá i pro DevOps typické metodické ukládání všech předchozích verzí kódu. Díky nim lze velmi rychle identifikovat případný problém, který může nastat po vydání nové části aplikace.
Když už k chybě dojde, stačí aplikaci jednoduše vrátit na předchozí verzi – zabere to maximálně pár minut. Vývojáři poté v klidu daný bug opraví zatímco uživatel aplikaci může bez potíží používat. Hledání eventuální chyby je také mnohem snazší, protože vydávaná část aplikace, ve které je potřeba bug najít, je velmi malá.
5) Bezproblémová automatizace a škálovatelnost
Kontejnerová technologie také výrazně zjednodušuje škálování a pomáhá DevOps týmu automatizovat některé činnosti. Například tvorbu a nasazování kontejneru lze automatizovat přes API, což přispívá k úspoře času a nákladů na vývoj.
Co se škálovatelnosti týče, aplikace můžete provozovat v libovolném počtu instancí kontejnerů, a to podle aktuální potřeby. Počet kontejnerů lze téměř okamžitě navyšovat (například během vánoční špičky) nebo naopak snižovat. Díky tomu ušetříte velkou část nákladů na infrastrukturu třeba v období, kdy poptávka po vašem zboží není tak velká. Zároveň když se zájem nečekaně zvedne – řekněme, že jste online lékárna v době pandemie – kapacitu bleskurychle navýšíte a hotovo.
6) Detailní monitoring byznysových metrik
K DevOps i kontejnerizaci nevyhnutelně patří i detailní monitoring, který pomáhá rychle identifikovat chyby v kódu. Monitoring je ale klíčový i k měření byznysových metrik. Díky nim můžete vyhodnotit, zda právě vydaná změna pomáhá dosáhnout vašich cílů nebo ne.
Pro představu: dejme tomu, že jste se u svého e-shopu rozhodli pro redesign domovské stránky, jehož cílem je zvýšení počtu objednávek o 10 %. Díky detailnímu monitoringu brzy po vydání zjistíte, jestli jste vytyčených 10 % dosáhli či nikoliv. Kdybyste oproti tomu udělali 5 změn v e-shopu najednou, bude vyhodnocení účinnosti jednotlivých opatření mnohem složitější. Řekněme, že celkovým výsledkem těchto 5 změn je zvýšení počtu objednávek o 7 %. Která z novinek způsobila největší nárůst? A nezpůsobuje naopak některá z nich snížení počtu objednávek? Kdo ví.
7) Agilnější a rychlejší vývoj
Výsledkem všeho výše uvedeného je významné zrychlení celého procesu vývoje, od napsání kódu po úspěšné spuštění daného softwaru, a to i o 60 % a více.
Jak moc velké bude zefektivnění, tedy i úspory a potažmo nárůst tržeb, ovšem závisí na mnoha faktorech. Mezi ty nejdůležitější patří velikost vašeho vývojového týmu a míra využití podpůrných nástrojů, jakými je například technologie kontejnerizace, automatizace procesů a volba flexibilní infrastruktury. Zjednodušeně řečeno, čím větší tým máte a čím více využijete možností automatizace a flexibility zvolené infrastruktury, tím efektivnější celý proces bude.
8) Menší náklady na vývoj
Asi nikoho nepřekvapí, že rychlejší vývoj, lepší komunikace a spolupráce týmů zamezující zbytečné práci a menší výskyt bugů napomáhá snížení nákladů na vývoj jako takový. Zejména u firem s většími IT týmy může jít i o desítky procent (!).
Často se i ukáže, že díky synergiím a větší efektivitě spojeného týmu nepotřebujete mít ve firmě 20 IT specialistů, ale třeba jen 17. A to je také pořádný rozdíl v rozpočtu.
9) Spokojenější zákazníci
Akcelerace vývoje vede také k větší spokojenosti zákazníků. Váš byznys je totiž schopen pružněji reagovat na jejich požadavky a například do e-shopu přidat novou funkci, po které vaši klienti volají. Díky detailnímu monitoringu také lépe odhalíte, které změny zákazníci vítají a které je lepší zahodit. Snáze se tak odlišíte od konkurence a vybudujete si základnu skalních fanoušků, kteří jen tak jinam nakupovat nepůjdou.
Co si z toho odnést
Když si to shrneme, z vývojářského pohledu DevOps spolu s kontejnery usnadní a urychlí práci, zlepší komunikaci s adminy a drasticky sníží výskyt bugů. Byznysově to znamená výrazné snížení nákladů a větší spokojenost zákazníků (a tedy i vyšší tržby). Z toho plynoucí rovnici „vyšší tržby + nižší náklady = vyšší ziskovost“ netřeba rozvádět.
Aby všechno fungovalo, jak má, budete také potřebovat dobrého poskytovatele infrastruktury – typicky nějakou formy Kubernetes platformy. Většinu z vás nejspíš jako první napadnou tradiční cloudy od amerických firem. Bohužel, podle zkušeností našich klientů vám uživatelská (ne)přívětivost těchto providerů celý proces příliš neusnadní. Další variantou je poskytovatel, který vám Kubernetes platformu předpřipraví, zdarma poradí co a jak a poskytne vám nonstop podporu na telefonu. To v češtině a za výrazně nižší cenu. Nechceme se chlubit, ale přesně tohle splňuje Kubernetes platforma od vshosting~.
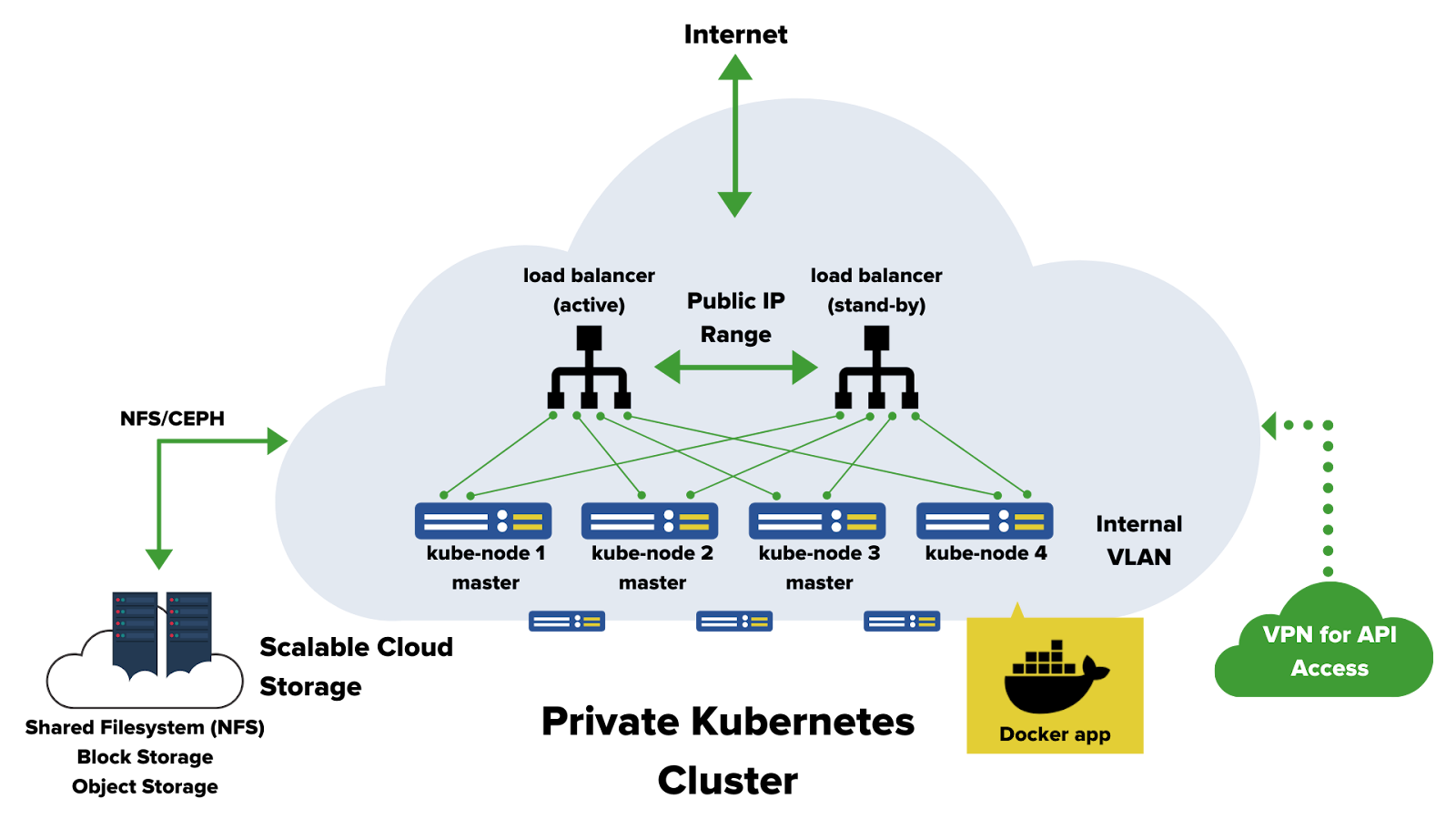
Příklad infrastruktury využívající kontejnerovou technologii – vshosting~